

In a machine learning project, much emphasis is often placed on the model development phase, where data scientists can walk through all the steps necessary to build a successful and robust prototype. These steps are widely consolidated and consist of data collection, proper labeling, model selection, training, performance evaluation on the test set, and final deployment to production, as part of an inference pipeline. So far it would seem that the data scientist’s work is done and the model can operate forever without particular issues.
The truth is quite different because many things can happen: real-world data could perform worse than test set, the behavior of the phenomenon could change over time, new classes are introduced, and observed features change. When a model tested at 95 percent accuracy is then put “online,” it may unexplainably occur that it performs at 80 percent or even less. A more active approach is therefore needed even when the model is released and operative.
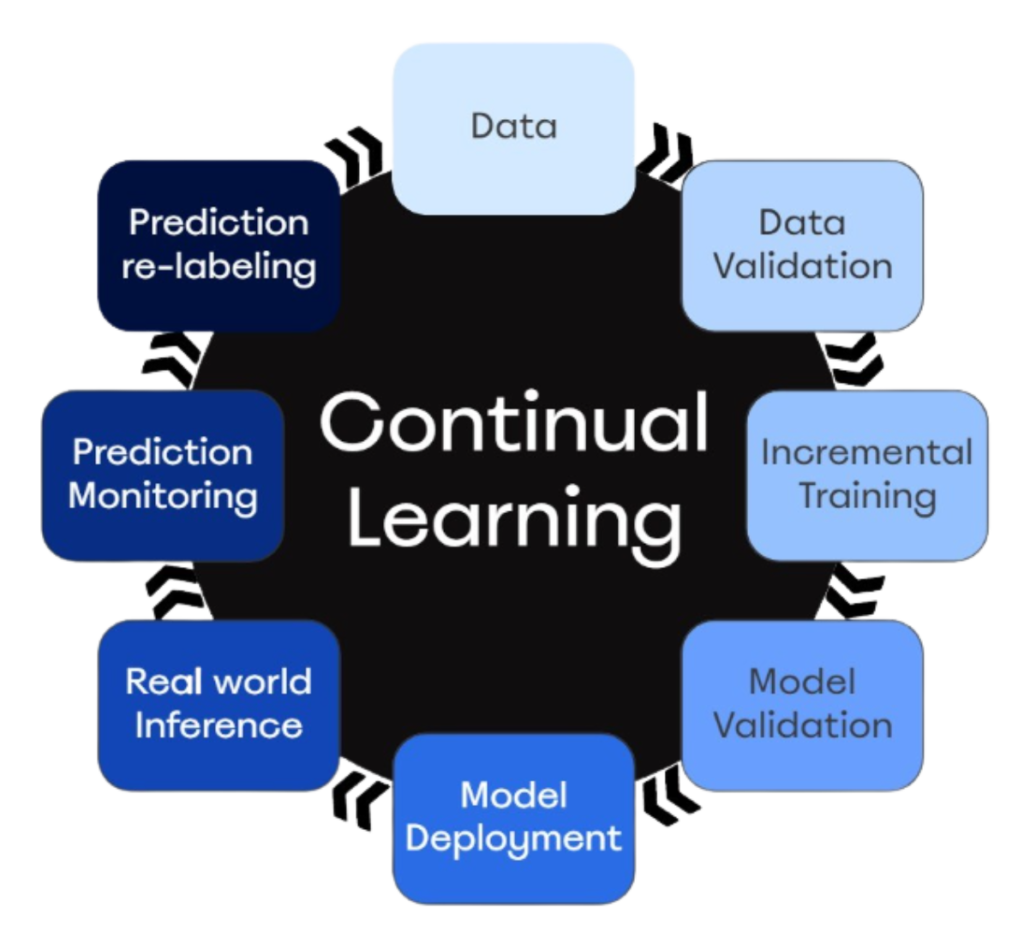
In this case it is strongly recommended to implement the Continual Learning Strategy Loop. Continual Learning is a technique that allows the model to learn continuously from a stream of new data. In practice, it means that the model adapts to new data, operating incremental re-training and building new knowledge on previously learned knowledge. In this way, one should expect a continuous increase in performance until reaching a plateau, which represents the intrinsic limit of the model and the phenomenon being analyzed.
Why is the term Loop used? The answer is simple: all the typical activities of the prototyping phase, are replicated cyclically, often automatically, with the only difference that the used data includes new data coming from the production environment. The missing ring that completes the circle is the monitoring of the predictions made by the model, which often involves human supervision in order to correct the labels and put new, clean data back into the loop.
There is only one issue that can make the Continual Learning process tricky: the problem of Catastrophic Forgetting. Basically, the data scientist must prevent the model from forgetting what was previously learned for the sake of new data. The simplest solution is a re-training performed on all data, both old and new, although this can lead to computational and storage resource problems over time. More often differing strategies are used including: Node Sharpening, Layers Freezing, Rehearsal Mechanism, Latent Learning and Elastic Weight Consolidation.
This article has been written by Giovanni Nardini – R&D Artificial Intelligence Lead